
Are chatbots living up to their promises?
The answer is complicated. While on the technical side bot-building frameworks, services, and libraries keep getting better, chatbots’ ability to understand their users and express themselves needs to be more refined for mass adoption. Let’s dig in to figure out the underlying challenges of natural language processing and achieving a natural-like expression. The chatbot industry is now worth millions (billions?), yet do you use chatbots daily? Do you know any friends that do?
Let’s dig in to figure out the underlying challenges of natural language processing and achieving a natural-like expression.
Before we do so, let’s state what’s on the menu. We’ll go back to the roots of chatbots, looking at what NLP really is and why it’s so hard. Then, we’ll look at currently available chatbots and analyze their shortcomings. With all this stated, we’ll be able to go back to the linguistics side of it and understand what is required to achieve a genuinely natural like expression.
Finally, loyal readers who stuck with me until the end can go a little further with the transcript of a quick exchange I had with Brett Scott while researching this article: we discuss the darker sides of chatbots — automation, speaker obfuscation, and data harvesting.
There are mainly two ways to build a chatbot: rule-based bots and chatbots relying on Artificial Intelligence (AI).
- Rule-based chatbots: these are the simplest — if the user says A, the bot will say B. For instance, a weather bot will respond back with the weather in Los Angeles to the query “weather + LA.” Rules can have some flexibility built-in, to work correctly even if the user inputs the command with a typo for instance. However, the bot will not be able to process an unknown query.
- AI-based chatbot: this approach is entirely different. These bots can analyze the language of the user to extract meaning out of it and answer accordingly — they can process an unknown input. To do so, AI-based chatbots use a technique called Natural Language Processing (NLP).
This dichotomy seems too nice to be true? It’s because it is! Chatbots in the wild are quite often made of a mix of both approaches: they follow a complex decision-tree logic and use NLP to make unknown statements fall back into one of the branches of their tree.
The tree logic is straightforward so we won’t detail it in in-depth. What’s more interesting is Natural Language Processing. Besides, it’s not only a bot matter: NLP powers all form of automated language recognition, ranging from sorting through a pile of resume to sentiment analysis on social networks.
Natural language processing: the key to smart chatbots
Natural language processing (NLP) is a way for computers to analyze, understand and derive meaning from human language.
iCapps
iCapps gives a pretty clear and straightforward definition of NLP . Essentially, the goal of NLP is to create programs able to understand regular, every-day language inputs instead of having the user pre-process his queries to make them understandable by a machine (The early “Siri” talk).
To do so, NLP relies on six key steps. We’ll detail what lies behind each of these steps to make the link between a written prompt to natural language expression analysis:
Tokenization
Before processing any written prompt, the text must be broken down into words and sentences to facilitate the analysis. In that regard, tokenization is pre-processing: it identifies the basic units (words and sentences) that will be processed during the analysis. While this step may seem basic, the tokenization must be accurate for the rest of the analysis to be relevant. Indeed, since tokenization is the first step of NLP, errors made here will propagate and cause problems of interpretation later on.
While it may seem basic (words are separated from each other by spaces, duh!) the reality of tokenization is more complex: “Los Angeles” is an individual entity even though it’s made of two words. “I’m” is two words and two different ideas without any blank space between them. Besides, NLP techniques may be applied to “dirty texts” — prompts that contain spelling mistakes, incorrect spacing, or improper use of punctuation — making it even trickier.
Therefore, different methods of tokenization have been developed, each with their strengths and weaknesses. The IBM’s developer blog article on the subject is a good starting point to learn more about it. Tokenization methods are not absolute: they are chosen and adapted depending of the nature of text analyzed.
Lexical Analysis
With a successful tokenization process, the words are properly separated from each other. Naturally, the next step is to categorize the tokens to facilitate their processing. An effortless way to classify the tokens is to **use an already existing categorization of language **— the grammatical nature of the words.
 _The linguistics behind chatbots — _iCapps
_The linguistics behind chatbots — _iCapps
First, it’s convenient because the match between a word and its grammatical nature is easily done using a dictionary. On top of that, because grammar is the set of rules governing the composition of clauses and phrases in the language, sorting tokens with the grammatical criteria makes the following steps easier, especially the next one: the syntactic analysis.
Syntactic Analysis
While the tokenization and the lexical analysis happen at the word level, the syntactic analysis jumps to the sentence level to identify the relationship between each word.
Essentially, it takes you back to school: article + adjective(s) + noun = subject group and so on.
 _The linguistics behind chatbots — _iCapps
_The linguistics behind chatbots — _iCapps
The syntactic analysis provides order and structure of each sentence in the text. Identifying the subjects, for instance, is particularly important for one of the following steps — discourse integration — which looks at the context around each sentence.
Semantic Analysis
In this step, the computer looks for the meaning of each word. What may once again seem like a simple step for a human (we have dictionaries for this, duh!) is trickier for a computer.
Some words are straightforward and therefore easy to interpret — “monosemy” for instance is the perfect body and soul example: it’s a noun referring exclusively to “the property of having only one meaning.”
The intended meaning can be much harder to figure out for polysemic words. “Set” has 119 different meanings and can be used as a transitive or intransitive verb, a noun, an adjective, an interjection as well as taking part in verb phrases (such as “set back”) and in idioms (such as “all set”).
The previous steps facilitate this one to some extent. Indeed, if we know that “set” is used as a noun, we’re down to 28 possible different meanings. Context is crucial here to find out the meaning intended by the speaker.
Discourse Integration
Discourse integration looks at the significance of the sentences compared to the preceding sentences. Cohesion between following sentences of the text is assumed.
To achieve this, the key lies in pronouns which must be correctly recognized as such and then linked to the relevant antecedent. For instance, in the following statement the computer needs to be able to properly recognize “it” and link it to “Google”:
Google is a search engine. It helps individuals find the information they are looking for online.
While this example is really straightforward. Yet, a real, natural sentence rarely is. Anaphoric references can be hard to interpret, especially in natural language where pronouns antecedents can be unclear or missing.
Pragmatic Analysis
Pragmatics study the ways context contributes to meaning. It’s the step going from what is said to what is meant, which is the hardest of the six steps. Ambiguity is hard to handle with computers, yet this is all we do while we humans talk. Depending on languages and situations, context can be more or less important.
Even human linguists have a tough time defining methods to analyze what meaning is brought by the context. Diverse theories emerged to account for the referential use of language such as Jakobson’s six functions of language (Referential, Poetic, Emotive, Conative, Phatic and Metalingual) or the Speech Act Theory (Which studies performative utterances — a statement that produces an act by itself such as “The meeting is now adjourned.). Defining what is context is already a hard job for a linguist; contextual awareness is arguably the hardest part of NLP.
Why do they fail? The seven sins of chatbots
Currently available chatbots most often fail to meet the expectations of users for reasons ranging from design issues to technical limitations. Fabricio from UXdesign.cc sums up, predominantly from a design perspective, the seven sins of chatbots. Here’s my take on it:
Limited AI availability
Even though NLP platform and libraries are becoming more accessible and common, AI is still hard and costly to implement. What this means is that despite the technological hype behind chatbots, a large part of the currently deployed bot base is still relying on a word-triggered, decision-tree logic to answer the queries. This type of bot is only as intelligent as the thoroughness of the person who designed the tree and his ability to anticipate potential use cases and inputs.
Even though these bots might be efficient in certain specific contexts, they also quickly generate frustration because of their lack of linguistic capabilities. They are quite often at a loss when faced with the way we talk in the real world: abbreviations, ungrammatical phrasing, spelling mistakes… Moreover, because of their tree-based decision logic, they are not able to respond appropriately to non-anticipated use cases:
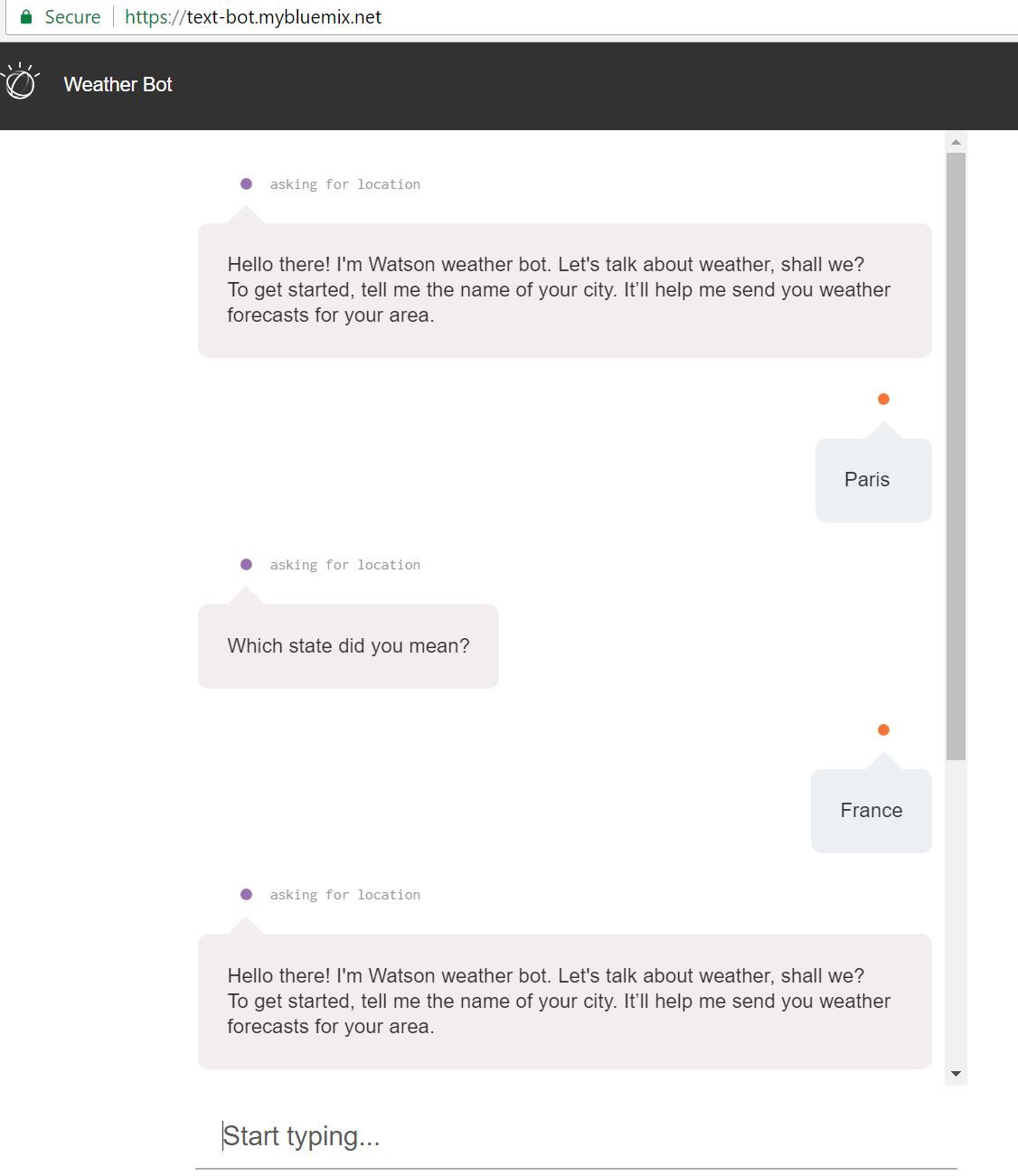 A weather bot fooled by the ambiguity between Paris, the capital of France and all the others (20+) Paris in several US-states.
A weather bot fooled by the ambiguity between Paris, the capital of France and all the others (20+) Paris in several US-states.
Are use cases really that strong?
When innovative technologies are emerging, they tend to generate a particular excitation among the developers’ and designers’ communities. Just like the apps, or the website before that, chatbots are becoming a must-have for any business who wishes to appear innovative. There’s a chatbot gold-rush leading to the development of bots solving irrelevant use cases or offering sub-par customer experience.
This leads to a multiplication of ill-conceived bots either missing to fit a real use case or just doing it worse that the existing solutions (sites, apps): dad jokes bots, personal florist bots, weather bots… See Darren Orf’s hall of horrors on the matter: Facebook Chatbots Are Frustrating and Useless.
Good chatbots, on the other hand, are those who solve a problem in a more convenient and straightforward way that websites or apps would have done. For instance, Kip is a Slack bot made to simplify the handling of grocery and food collective orders at the office. The efficient usage of Slack’s built-in functions allows @Kiptalk to be handy and reactive.
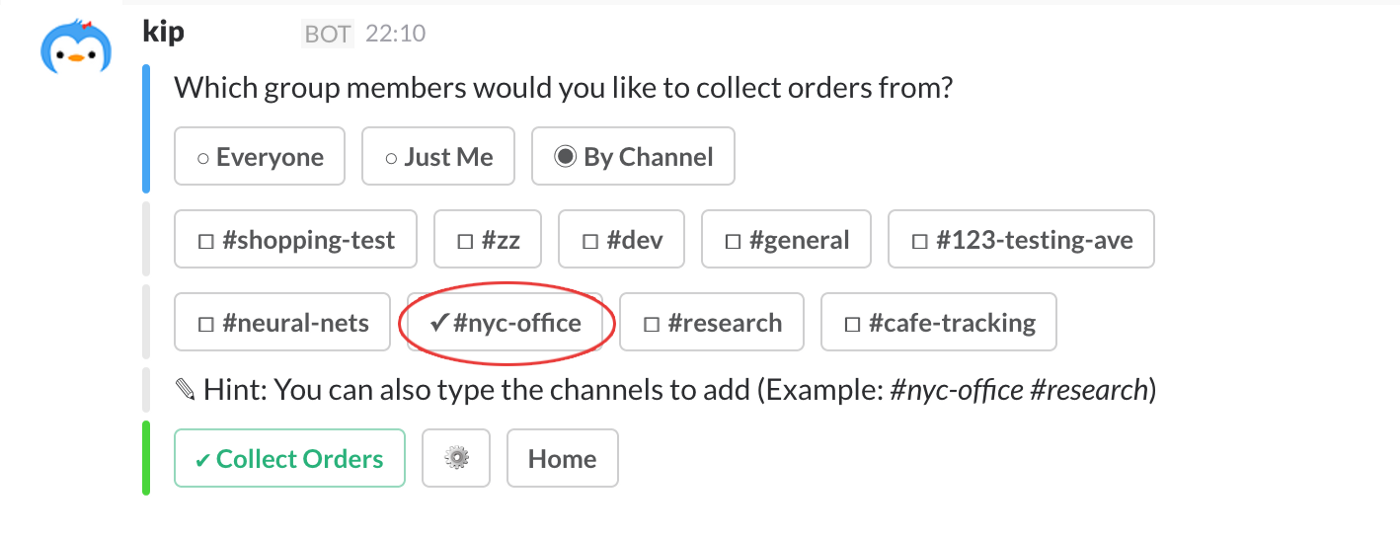 Kip Slack bot in action
Kip Slack bot in action
Lack of transparency: Who/Whom am I talking to?
The way chatbots present themselves frame the user interaction. Even though bot-makers want to make them feel as human as possible, they must remember the importance of setting up the right expectations. People are empathetic towards other people, not machines.
The choice between a “humanized bot” and a bot assuming his mechanical identity is hard; essentially, it boils down to the relationship you’re looking to build between your chatbot and its users. Users tend to be more patient and willing to tolerate mistakes made by a bot who’s honest about its robotic nature.
While giving bots generic pre-made answers to use while he doesn’t understand a query can help maintain the conversation flow, does it help to build trust?
Lack of context awareness
Human conversation is hard to replicate because of its reliance on context: we use and understand sarcasm, adapt our way of chatting depending on the channels and the persons we address (see Jakobson’s phatic function of language) and can read between the lines. Bots can’t.
Imagine you have a friend coming over to your place:
Friend_: “Do you have beers?”_
You_: “Help yourself.”_
With nothing more than these two words, your friend infers that you do have beers, that they’re probably in their usual place and he can grab one or two if you’re drinking too.
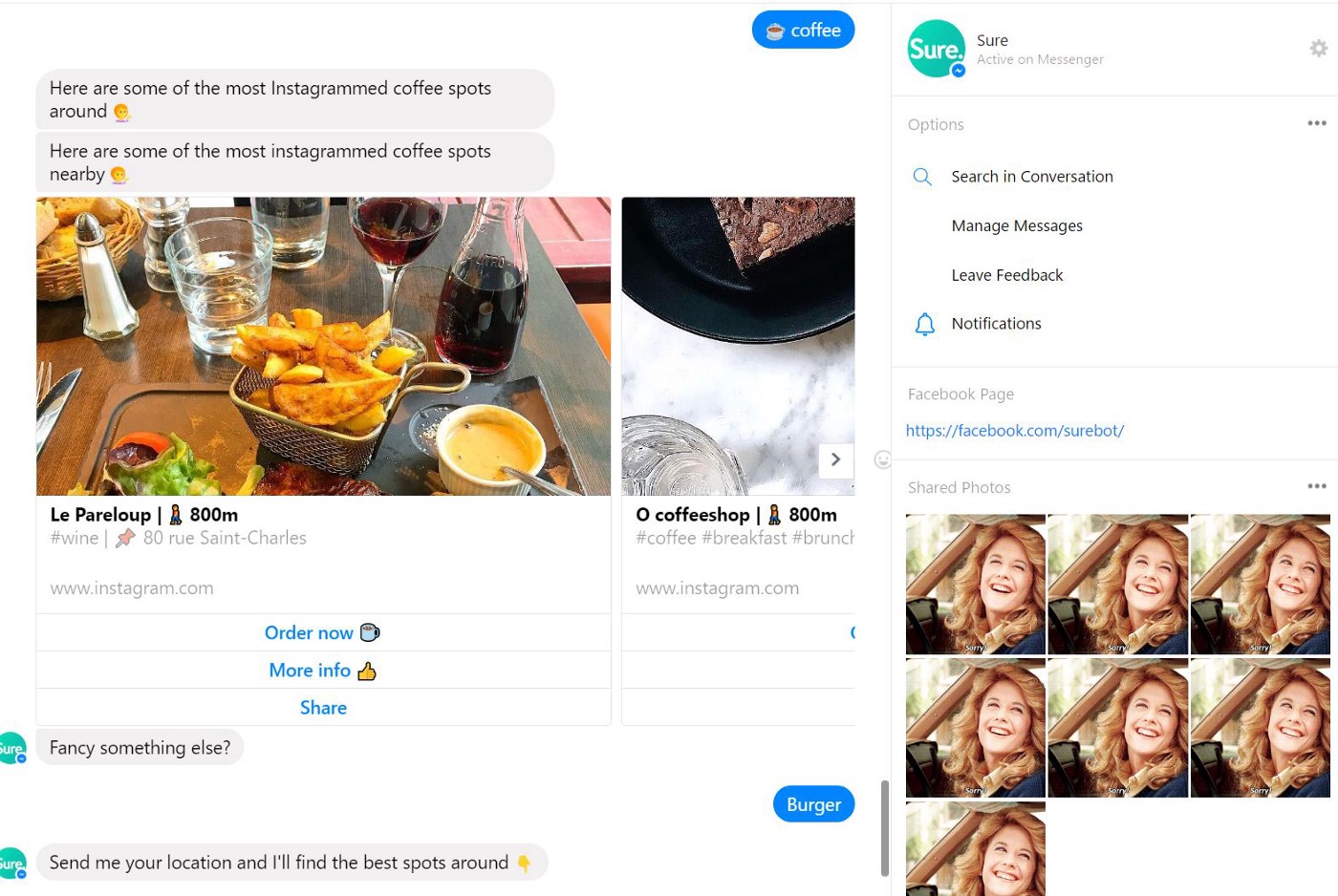 Sure chatbot is asking for your location at every query.
Sure chatbot is asking for your location at every query.
Bots that are not powered by natural language processing technologies can’t hold contextual information for a long time. They may lose track of what the customer is saying before he asks his question.
Because of this shortcoming, we can’t exchange with the bot naturally, we must adapt our prompt to include location each time we ask him something.
Lack of communications with existing business systems
To be efficient, bots need to be able to interact with current business processes instead of creating new ones. Ultimately, chatbots are part of a broad ecosystem constituted of numerous touch points between customers and brands.
Creating a chatbot operating in silo not only hurts the bot’s ability to process and respond to users’ queries; it also makes it harder for the business to handle the requests generated by the bot channels.
Only bots able to interact with pre-existing business processes can consistently produce value, such as Kip discussed before: he orders the item specified on the grocery list collected with Slack using Amazon.
Lack of focus
Efficient bots tackle specific issues where they can provide more value than their pre-existing counterparts (website, apps, or any other mode of interaction).
The pre-existing channels to solve the defined user problem must be thoroughly studied to make a chatbot that is an improvement regarding the design and efficiency of the interaction.
Moreover, lack of focus can result in a bot that is both hard to develop and to maintain.
Lack of human escalation protocol
Bots are not the answer to all customer interactions. Even though the temptation of automation is understandable for businesses with many clients, there are always situations where a human touch is required.
These situations must be thought of and included in the bots’ decision tree/actions. Indeed, without proper escalation, these situations result in a user left hanging, probably frustrated by their unsuccessful interaction with the bot.
The current dominant business perspective tends to see chatbots as a way to reduce the need for real humans to handle customer interaction. The truth of efficient and engaging bots is the opposite: they’re used to create a new interaction channel where a real person will be available if required.
With a better understanding of what NLP is, from a linguistic perspective and why primary reasons behind current bots’ failure, it’s time to go back to the linguistics and explore what bots need to achieve a truly natural-like expression.
Since linguistics features vary per language, we’ll focus only on English, which is the most common language for bots and the one for which the research is the most advanced.
How to achieve truly natural-like expression?
Vocabulary: quantity is easy, polysemy is not
Depending on the estimates and the way a “word” is defined, there are around 500,000 words in the English language. Most of them are very rarely used: they may be obsolete, part of a field-specific jargon or register-specific.
Indeed, an educated native English speaker has an active vocabulary of roughly 50 000 words (Words in the Mind: An Introduction to the Mental Lexicon — Jean Aitchison and Detlef Stark). Once again, out of these 50,000 words, few of them make for most of our texts. Frequently used words include the most flexible: verbs, prepositions, and pronouns. Research indicates that 2,145 words account for 80% of all English text (The linguistic accuracy of chatbots: Usability from an ESL perspective — David Coniam).
As the analysis of the semantic analysis challenges proved, the difficulty does not lie in the quantity of vocabulary to apprehend but in its flexibility: polysemy is tough to compute. We have access to context to sort out between the dozens of potential meanings of a word to find the one relevant to our current situation. Currently, chatbots have little to no context awareness; they must rely on other strategies.
The maxims of an honest chatbot
While we talk, a lot of the transmission of meaning happens by the choice we make.
When photographer takes a picture, he gives it an angle, saturation, a particular framing — ultimately, he translates his perspective, his view to what is in the most basic sense a very truthful representation of the real world.
We do the same with language. We choose to talk about certain things and not others, use specific words to refer to what we meant, order these words a certain way among all the possibilities… Those choices carry meaning by themselves.
Therefore, we’re left to guess why the person talking to you made these linguistic choices. Our analysis is not purely intuitive or random. To understand the implicature of prompts (the implied meaning) we rely on a few fundamental principles.
Herbert Paul Grice studied semantics and is well known for his theory of implicature. He isolated four main maxims we use to understand implicatures:
- Maxim of Quantity — we make the information we give as informative as required (for the current purpose of the exchange), but not too detailed (which would hinder comprehension).
- Maxim of Quality — we try to make a contribution that is true. Which means to omit saying what we believe is false but also avoid talking while lacking sufficient evidence.
- Maxim of Relevance — we try to stay relevant and say things that are pertinent within the context of the discussion… A tough one for a bot!
- Maxim of Manner — we try to make ourselves easy to understand. This means to stay as concise as possible, avoid ambiguity, make ourselves clear and try to stay orderly.
We have an intuitive understanding of these maxims and expect every speaker we encounter to follow them as much as possible. While the people we talk with don’t do so, we tend to get frustrated by the exchange which becomes either hard to follow (too much quantity / not enough quality / not relevant enough / lack of manners) or not informative enough (lack of quantity or quality).
It’s safe to expect that we hold the chatbots — if they are natural enough — up to the same standards.
The bot’s self-reference: what/who are we talking to?
Despite the advanced tech behind chatbots, the though-process on their design and “personality” is still at a very early stage. Indeed, the submissive female persona in still very prevalent in bots. Moreover, bots who can process and answer queries with audio predominantly adopt a female voice for speech generation. Siri, probably the most famous virtual assistant was released at first with a female voice in 2011. The option to give a male voice to Siri only came two years later.

Some bot-builders avoid the gender definition issue by crafting gender neutral persona. For instance, Kip, the slackbot discussed earlier use a penguin mascot as its persona.
Essentially, bot builders have three options when it comes to the chatbot self-reference:
- Avoid it all together: diverse self-reference avoidance strategies can be enforced such as using a gender-neutral mascot, or producing an evasive answer when the bot is asked directly what its gender is.
- Using the first person singular pronoun “I”: although the “I” is the simplest way to deal with this question, it also sets elevated expectations for the customers. If the bot fails to display a real personality, its self-reference might come up as purely artificial .
- Using the first person singular pronoun “We”: “we” can seem as a good middle ground. It might refer to the team behind the bot, or simply the team the bot is impersonating (such as the bank employees for a bank clerk bot). Yet, “we” has been already widely used to make business communications sound friendlier; a chatbot referring to himself as “we” might suffer from the “corporate we” fatigue.
Peter Wallis and Emma Norling researched the impact of social intelligence, or the lack thereof in conversational agents to deal with problematic situations such as a rude callers (The Trouble with Chatbots: social skills in a social world — Peter Wallis and Emma Norling). They highlighted the need for chatbots to be able to “play the game” to efficiently de-escalate conflicts.
An approach described in a forthcoming paper is based on the idea that emotions are basically a means of signaling escalation in conflict. Although lions can inflict life-threatening injuries on each other, fights usually stop well before this happens. In the same way, an abusive response might be a signal that the agent is willing to (emotionally) hurt the human, and that the human had better stop soon or risk being hurt. Although a human might not have any inhibitions about ‘hurting the feelings’ of a machine, _they might feel differently about being called a moron themselves _— even if it is by a machine.
Peter Wallis and Emma Norling
In search for the Honest Bot
We tend to get personal and emotionally invested with chatbots. Chatbotslife carried out an analysis of 10 billion messages sent to bots and noted that about 10% of bots receive an ‘I love you’ or ‘I hate you’ type of message.
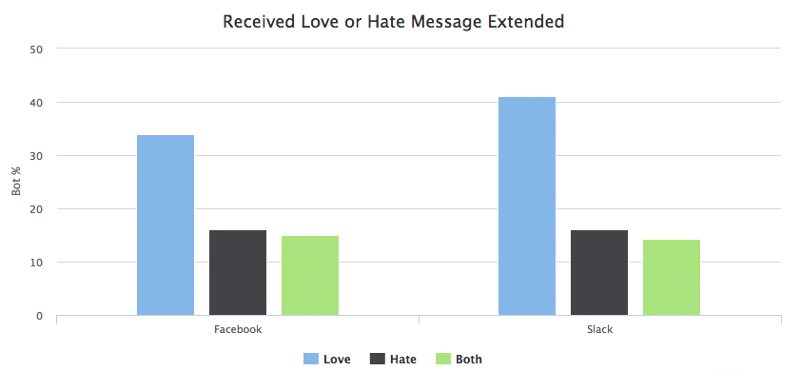 What 10 Billion Messages can Teach us About Making Chatbots –Chatbotslife
What 10 Billion Messages can Teach us About Making Chatbots –Chatbotslife
A lot is at stake behind the question of chatbots’ self-reference. Humans tend to mystify objects — we see objects for more than their mere physical existence: a Coke is not just soda, it’s a lifestyle. Brett Scott discusses this process called fetishization in his article If You Talk to Bots, You’re Talking to Their Bosses.
Indeed, the emergence of chatbots pushes the boundaries of corporate personhood. Companies already have legal personalities; bots can give them another layer of pseudo-humanity with a conversational and artificial personality blurring, even more, the frontier between corporations and individuals.
The Honest Bot does not currently exist. The new wave of bots are — to use a term popularized by the existentialist misfit Holden Caulfield from The Catcher in the Rye — the ultimate phonies. They’ll pretend to be friendly, to be cool, to be serious, to be insightful, and even to be self-reflective. But they’ll never just be themselves. Because, in the end, there is no “I.” There is only a company, its shares held by who knows who, possibly registered in Panama.
Brett Scott
While bots are now mostly seen as a new, practical way for the consumer to interact with brands, the search for the honest bot showcases the deep stakes of the chatbot industry. As the personalization of chatbots gets more and more precise, so does the data collected on each user.
It can end up being resold and consolidated with other databases fulfilling the economic agenda of the bot’s owners and bot-platforms. The end-user might be left even more vulnerable than before to intrusive data-collection and advertising methods.
Now is the time to question what are the benefits to be gained from chatbots and who will harness those benefits. We should remain alert towards the hype and make sure we truly benefit from bots, not the other way around. Once they’ll be part of our everyday life, it’ll already be too late.
This article was first published May the 31st 2017 on CALLR’s blog and slightly modified for Medium.
Chatbots’ role and challenges — a quick exchange with Brett Scott
While I was researching this article, I had the chance to have a quick exchange with Brett Scott about chatbots’ perceived roles and their current limitations. I figured it would be a good way to wrap this one up, as we discuss some themes addressed by this article and explore a few others that are related. Thanks again Brett for the quality insights!
Here is the transcript:
Do brands crave chatbots because they are looking at automating certain positions (support, customer relations, etc.) previously handled by real, human workers?
- New companies that have never hired front-line workers and that are **starting out with an automated customer process **— a lot of Silicon Valley companies are like this e.g. AirBnB has never had actual customer-facing staff.
- Old companies that previously have had front-line customer-facing workers and who are now looking to provide a lower-cost option, potentially with a view to eventually getting rid of the front-line workers e.g. a lot of banks are like this.
- In the latter context, the chatbot is seen as a more ‘human’ experience’ than just giving them a webpage or app with options.
Isn’t the lack of human touch frustrating considering the current state of chatbots? Are chatbots a real improvement in terms of UX?
- In terms of whether the UX is authentically improved, I don’t know — I suspect a significant number of people could find chatbots pretty irritating, and might just prefer a normal interface. The key difference with the normal interface though, is that it limits your queries through predefined categories, whereas the chatbot creates the illusion of being able to request or ask anything.
- I guess then the NLP stuff is about being able to fit those badly-spelled or strangely phrased queries into predefined categories that can be answered (as far as I know chatbots cannot yet improvise or make up answers or engage in spontaneous actions — they can only learn to take in unpredictable inputs and give out predictable outputs)
In a brand perspective, chatbots embody a new interface to interact with customers. What are the characteristics of chatbots — as interfaces — compared to the usual ones (website, apps…)?
- We can have a general critique of interfaces in that they obscure what goes on behind them and we might argue that the chatbot is particularly good at that because it presents a human or ‘confidential’ persona that lulls the user into thinking they are actually just interacting with a ‘being’ rather than an IT system.
Is data the main driver of chatbots’ adoption? — Are companies looking forward to implement chatbots because it allows them to collect even more data on their users?
- I’m not sure if the data extracted in this process is going to be greater than with any other digital interface, but perhaps.